Server Memory Architectures – Explained
This ability of computing is not only limited to the high performance environments but also in the normal desktop environments where the use of multiple processors has become synonymous to a ‘normal’ configuration. As this demand for computing is increasing, several solutions are being used to provide computing power for different types of applications.
With the desire for more computing power and better processing abilities, there have been a variety of technologies that have been adopted in the computer industry. From a single processor system, we have seen the systems grow to multiprocessor systems with the ability to execute applications independently on different processors.
This ability of computing is not only limited to the high performance environments but also in the normal desktop environments where the use of multiple processors has become synonymous to a ‘normal’ configuration. As this demand for computing is increasing, several solutions are being used to provide computing power for different types of applications.
Parallel computers can be broadly classified based on the level at which the hardware supports parallelism. The commonly used parallel computing technologies are –
Multicore computing – This method involves a processor that contains multiple processing cores on the same chip. A multicore processor can issue multiple instructions per cycle from multiple instruction streams.
Symmetric multiprocessing – This is a computer system that contains multiple identical processors that share a memory via a common bus. This prevents the bus architectures from scaling because of which such systems do not contain more than 32 processors.
Distributed Computing – In this method, the processing elements are connected using a network which makes them highly scalable
Cluster Computing – This method involves a group of loosely coupled computer systems that work together closely to project the presence of a single computer. Clusters usually contain multiple stand-alone machines that are connected by a network.
Each of these computing systems has their own independent challenges to be solved and the primary being the usage of memory. The main memory in a parallel computer is either a shared memory or a distributed memory. Distributed memory refers to the fact that the memory is logically distributed, but often implies that it is physically distributed as well. The processing element has its own local memory and has access to the memory on non-local processors. Accesses to local memory are typically faster than accesses to non-local memory.
Computer architectures in which each element of main memory can be accessed with equal latency and bandwidth are known as Uniform Memory Access (UMA) systems. Typically, that can be achieved only by a shared memory system, in which the memory is not physically distributed. A system that does not have this property is known as Non-Uniform Memory Access (NUMA) architecture. Distributed memory systems have non-uniform memory access.
Computer systems usually employ a small fast memories located close to the processor called caches which temporarily stores the copy of the memory values. Parallel computer systems have difficulties with caches that may store the same value in more than one location, with the possibility of incorrect program execution. These computers require a cache coherency system, which keeps track of cached values and strategically purges them, thus ensuring correct program execution. Designing large, high-performance cache coherence systems is a very difficult problem in computer architecture. As a result, shared-memory computer architectures do not scale as well as distributed memory systems do.
With this introduction, let us get in to some details of these Memory Architectures which this article targets to present in some detail.
Shared Memory Architecture
As the name suggests, this architecture consists of a single memory component that is shared across processing components. This suggests that processor(s) can make use of a single large chunk of memory or can have multiple memories which are then shared among them.
Unified Memory Architecture (UMA) is a type of a Shared Memory in which the different memory regions in a computer system are interconnected using a bus that are accessible by all processing units.
A typical UMA computer has the following hardware layout for the memory and the processors –
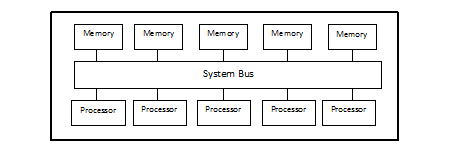
All the processors are identical and have equal access times to all memory regions. These are also known as Symmetric Multiprocessor (SMP) machines. In these computers, the processes can be movedto any processor because their memory area can be accessed by all processors with the same average cost. This property makes the load balancing much simpler in these systems.
Distributed Memory Architecture
Non Unified Memory Architecture (NUMA) is a type of the Distributed Memory Architecture in which, the memory is distributed separately among nodes and hence different memory areas cannot be accessed simultaneously. However, the memory access time depends on the processor that a process is executing on and the memory area that the process is accessing. The following figure shows an eight processor NUMA machine organized in to four nodes. In that machine, the CPU 1 accesses memory in node 1 faster than memory in nodes 2, 3, 4.
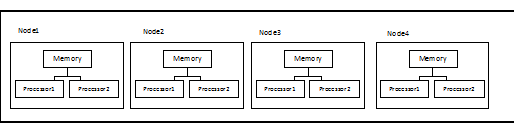
The computer depicted in this figure has two memory access levels pertaining to the time to access the memory: (i) access time to memory in the same node of the processor; and, (ii) access time to memory in another node. There are certain architectures with more than three access levels also.
In these computers, a load balancing algorithm must keep processes as close as possible to their memory areas. This feature makes a load balancing in these architectures a complex problem which depends on the number of access levels for memory.
With this detail on the architectures, let us look at their hardware level implementation considering two examples for UMA and NUMA each.
FSB (Front Side Bus)
This term was coined by Intel Corporation in the early 1990’s and the “Front Side” refers to the external interface from the processor to the rest of the computer system, as opposed to the back side which connects the cache and also other CPU’s.
A FSB is mostly used on PC-related motherboards and servers, seldom with the data and address buses used in embedded systems and similar small computers. This design represented a performance improvement over the single system bus designs of the previous decades, but sometimes is still called the “system bus”.
As shown in the following figure, FSB based UMA architecture has a Memory Controller Hub, which has all the memory connected to it. The CPUs interact with the MCH whenever they need to access the memory. The I/O controller hub is also connected to the MCH, hence the major bottleneck in this implementation is the bus, which has a finite speed, and has scalability issues. This is because, for any communication, the CPU’s need to take control of the bus which leads to contention problems. These contention problems further increased with the number of processors (cores) and the need for a new memory access strategy surfaced.
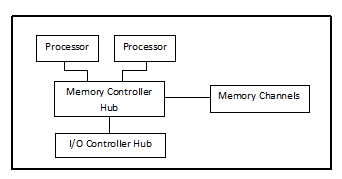
QPI (Quick Path Interconnect)
The Intel QuickPath Interconnect is a point-to-point processor interconnect developed by Intel which replaces the front-side bus (FSB) in certain desktop platforms. It was designed to compete with HyperTransport developed by AMD.
In its simplest form on a single-processor motherboard, a single QPI is used to connect the processor to the IO Hub. In more complex instances of the architecture, separate QPI link pairs connect one or more processors and one or more IO hubs or routing hubs in a network on the motherboard, allowing all of the components to access other components via the network. The QuickPath Architecture assumes that the processors will have integrated memory controllers, and enables a non-uniform memory access (NUMA) architecture.
The key point to be observed in this implementation as shown in the figure below is that the memory is directly connected to the CPU’s instead of a memory controller. Instead of accessing memory via a Memory Controller Hub, each CPU now has a memory controller embedded inside it. Also, the CPU’s are connected to an I/O hub, and to each other. So, in effect, this implementation tries to address the common-channel contention problems.
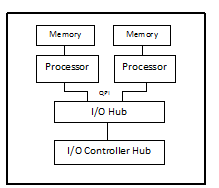
Operating System Considerations
With the increasing use of NUMA computers, the need for efficient load balancing algorithms in operating systems is necessitated. Operating systems try to achieve the major goals of Usability of Utilization in which the OS abstracts the hardware for programmer’s convenience and maintains an optimal resource management by multiplexing the hardware amongst different applications.
The solution to this is to make the OS NUMA aware where it discovers the underlying hardware topology and calculates the NUMA distance accurately. The NUMA distances tell the processors (there by the programmers) as to the time it would take to access a particular memory.
The OS should provide a mechanism for processor affinity to make sure that some threads are scheduled on certain processor(s), to ensure data locality. This not only avoids remote access, but can also take the advantage of hot cache. The operating systems needs to make sure that load is balanced amongst the different processors (by making sure that data is distributed amongst CPU’s for large jobs), so as to promote effective processor utilization.
We see here that the goals established initially become conflicting in nature, where, initially the attempt is to optimize memory placement to balance load and on the other hand we also attempt to minimize the migration of data to overcome resource contention. We can therefore say that the importance or precedence of these two factors is application dependent.
As an example, Linux implements the NUMA aware scheduler which keeps information about the home node of processes and attracts them back to their home nodes when they are moved.
The Linux load balancing algorithm (kernel version 2.6.11.51) uses a structures called sched domains that are hierarchically organized to represent the computer‘s architecture. Although sched domains implementation does not limit the number of levels it can have, the described Linux version builds no more than two levels. Consequently, for some architectures (with more than two memory access levels), the hierarchy will not represent the machine’s topology correctly, causing inappropriate load balancing.
Programming Considerations
NUMA aware programming approach aims at reducing the locking contention and maximizes memory allocation on local node. Also, programmers need to manage their own memory for maximum portability which can be quite a challenge since most languages do not have an in-built memory manager.
Programmers rely on tools and libraries for application development. The tools and libraries need to help the programmers in achieving maximum efficiency, also to implement implicit parallelism. The user or the system interface, in turn needs to have programming constructs for associating virtual memory addresses. The programmers need to explore the various NUMA libraries that are available to help simplify the task and can also exploit various parallel programming paradigms, such as Threads, Message Passing, and Data Parallelism to develop a NUMA friendly application.
